
I’ve always liked power analysis. Born of the Neyman-Pearson approach to significance testing, it rests upon a foundation of good measurement, the use of effect sizes, and good planning. It struck me as intrinsic to what we are aspiring to do as scientists–discover things, confirm them, then build upon that knowledge. If you do an exploratory study, you have the basic information you need to start using power analysis to your benefit. You can take the effect size estimate and use it to plan your next study and the next after that. I mean, if your effect is real and you actually believe it, why wouldn’t you use it so that your subsequent research isn’t a waste of time? There’s no better way to respect prior findings and thus prior scientists than doing a power analysis based on that prior work.
Of course, that’s not what we do. In my recent cursory review of three top journals from clinical, educational, and developmental psych a little over 20% of the papers reported conducting a power analysis when planning their research. That’s great right?
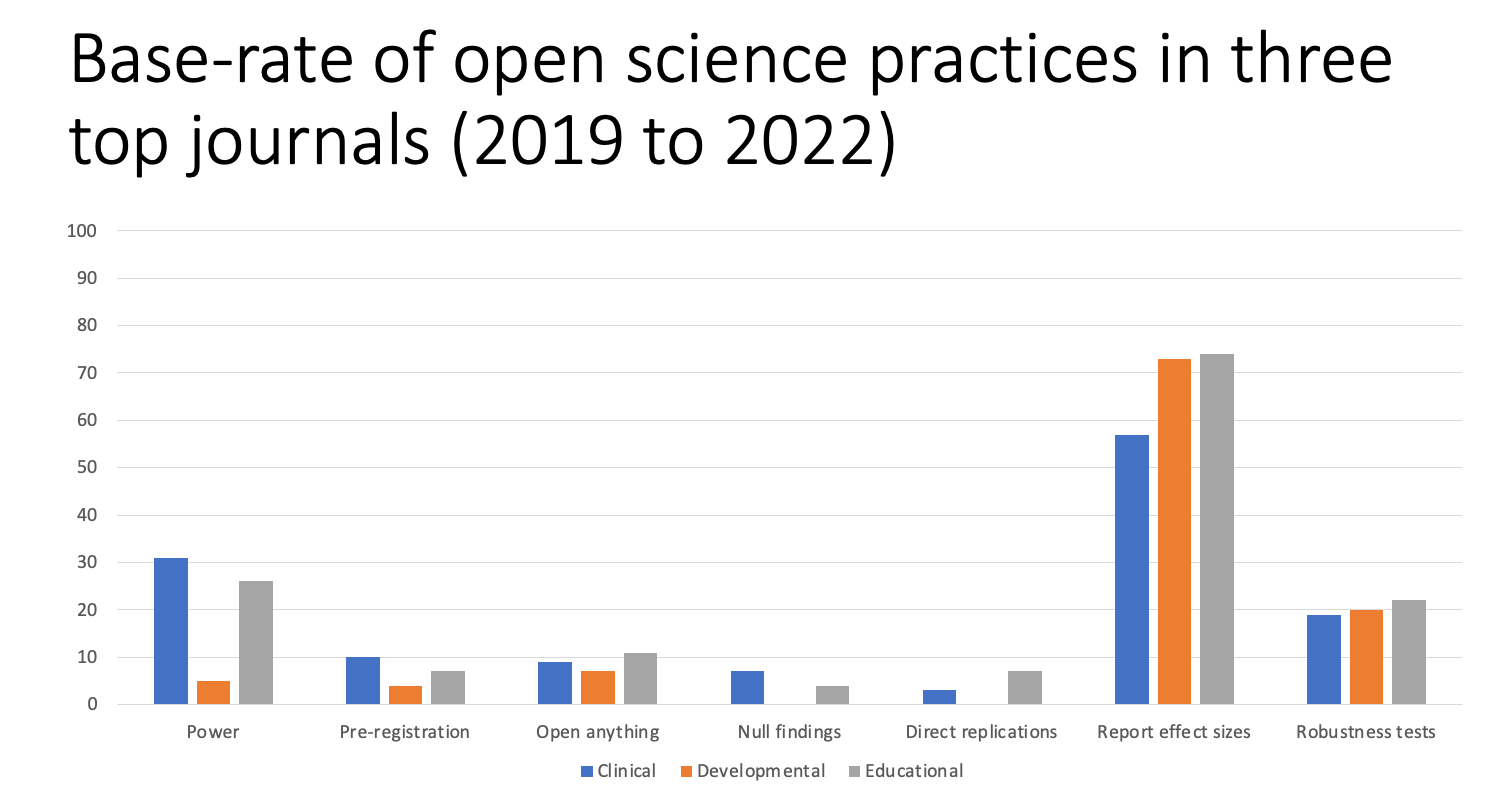
I mean, when one contemplates the number of reported power analyses in any published paper just a decade ago, this would clearly constitute an increase–there’s your glass half full. This rosy picture is backed up by the fact that the median number of participants in many journals has actually risen in the last decade (Fraley et al., 2022).
Considering the fact that granting agencies have required power analyses for several decades and that it has been one of the long-standing areas of criticism of modern psychology going back to the 1960s then 20% doesn’t sound so great. There’s your glass half empty.
When you consider the fact that almost all of the power analyses reported in grants and papers are fictitious that would be a clear fail–there’s your glass completely empty. Why do I make such an outlandish claim? I served for years on an NIH review panel. It only took a few rounds of grant reviews to realize that every single study ever designed in a grant had more than adequate power. And, the modal study design never changed–we didn’t see an increase in sample size in our scientific efforts due to the fact that granting agencies required power analysis. Why was power always more than adequate? Because, researchers weren’t estimating power from an objective read of their prior efforts. No, they were telling the reader what effect size they would report in the eventual publication confirming their idea that was curated from all of the studies they ran. That is, they were telling us their post hoc power for effects that were significant in the typical sample size they ran in their lab. Most people run studies large enough to find a medium effect size to be statistically significant. Thus, almost every power analysis reported that the authors expected to find a medium sized effect and thus every proposed study had adequate power. What they were doing, in a nutshell, was estimating Power After the Results are Known, or PARKing.
Power analyses reported in published papers often follow the same strategy or lack thereof. People report power analyses not because they actually used them in planning the study, but because the norms have changed enough that they get credit for reporting a power analysis even if it is a faux power analysis. Another strategy is to report a power analysis about the lone effect that might be of notable size and blithely ignore the lack of power to test all of the follow on ideas. This is most conspicuous when people test moderator effects which are almost never powered adequately. An ingenious cosmetic power strategy in these cases is to report doing a power analysis for the main effect and then plowing ahead with the interaction analyses anyway. After all, if they are statistically significant interaction effects must be real.
PARKing is a symptom of a more pervasive disease in psychological science. Or maybe it is an allergy. Collectively, we have an acute allergy to doing cumulative science. You see, if we did cumulative science then our work would build on prior efforts. How? Well, at a minimum, we would take seriously the effects we discover and design our studies accordingly. If the prior study reported a d of .4, then we should take that finding seriously enough to design our work to detect that effect size. Heck, more appropriately, we should take seriously our own effect sizes. It is too often the case that we run a study, find an effect, and then don’t use that effect size in our own follow up research. Why? Because our incentive system doesn’t care about accumulating knowledge. It only prioritizes novel contributions. In a world where novel contributions (read findings) are the capital of the land, there is absolutely no utility in building on others’ work or your own work for that matter. You just need the putatively novel finding and the appropriate p-value to claim an effect. Power analysis is for suckers who do boring cumulative work. And, thus, you see in our top journals PARKing structures galore if and when power analyses are presented. Of course, when 80% of the studies don’t report a power analysis we are still not building any scientific structures to rely on.
Fraley, R. C., Chong, J. Y., Baacke, K. A., Greco, A. J., Guan, H., & Vazire, S. (2022). Journal N-pact factors from 2011 to 2019: evaluating the quality of social/personality journals with respect to sample size and statistical power. Advances in Methods and Practices in Psychological Science, 5(4), 25152459221120217.
