The following is a hypothetical exchange between a graduate student and Professor Belfry-Roaster. The names have been changed to protect the innocent….
Budlie Bond: Professor Belfry-Roaster I was confused today in journal club when everyone started discussing power. I’ve taken my grad stats courses, but they didn’t teach us anything about power. It seemed really important. But it also seemed controversial. Can you tell me a bit more about power and why people care so much about it
Prof. Belfry-Roaster: Sure, power is a very important factor in planning and evaluating research. Technically, power is defined as the long-run probability of rejecting the null hypothesis when it is, in fact, false. Power is typically considered to be a Good Thing because, if the null is false, then you want your research to be capable of rejecting it. The higher the power of your study, the better the chances are that this will happen.
The concept of power comes out of a very specific approach to significance testing pioneered by Neyman and Pearson. In this system, a researcher considers 4 factors when planning and evaluating research: the alpha level (typically the threshold you use to decide whether a finding is statistically significant), the effect size of your focal test of your hypothesis, sample size, and power. The cool thing about this system is that if you know 3 of the factors you can compute the last one. What makes it even easier is that we almost always use an alpha value of .05, so that is fixed. That leaves two things: the effect size (which you don’t control) and your sample size (which you can control). Thus, if you know the effect size of interest, you can use power analysis to determine the sample size needed to reject the null, say, 80% of the time, if the null is false in the population. Similarly, if you know the sample size of a study, you can calculate the power it has to reject the null under a variety of possible effect sizes in the population.
Here’s a classic paper on the topic for some quick reading:
Cohen J. (1992). Statistical power analysis. Current Directions in Psychological Science, 1, 98-101.
Budlie Bond: Okay, that is a little clearer. It seems that effect sizes are critical to understanding power. How do I figure out what my effect size is? It seems like that would involve a lot of guess work. I thought part of the reason we did research was because we didn’t know what the effect sizes were.
Prof. Belfry-Roaster: Effect sizes refer to the magnitude of the relationship between variables and can be indexed in far too many ways to describe. The two easiest and most useful for the majority of work in our field are the d-score and the correlation coefficient. The d-score is the standardized difference between two means—simply the difference divided by the pooled standard deviation. The correlation coefficient is, well, the correlation coefficient.
The cool thing about these two effect sizes is that they are really easy to compute from the statistics that all papers should report. They can also be derived from basic information in a study, like the sample size and the p-value associated with a focal significance test. So, even if an author has not reported an effect size you can derive one easily from their test statistics. Here are some cool resources that help you understand and calculate effect sizes from basic information like means and standard deviations, p-values, and other test statistics:
https://sites.google.com/site/lakens2/effect-sizes
Faul, F., Erdfelder, E., Lang, A.-G., & Buchner, A. (2007). G* Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191.
Budlie Bond: You said I can use effect size information to plan a study. How does that work?
Prof. Belfry-Roaster: If you have some sense of what the effect size may be based on previous research, you can always use that as a best guess for selecting the appropriate sample size. But, many times that information isn’t available because you are trying something new. If that is the case, you can still draw upon what we generally know about effect sizes in our field. There are now five reviews that show that the average effect sizes in social, personality, and organizational psychology correspond roughly to a d-score of .4 or a correlation of .2.
Bosco, F. A., Aguinis, H., Singh, K., Field, J. G., & Pierce, C. A. (2015). Correlational effect size benchmarks. Journal of Applied Psychology, 100(2), 431.
Fraley, R. C., & Marks, M. J. (2007). The null hypothesis significance testing debate and its implications for personality research. Handbook of research methods in personality psychology, 149-169.
Paterson, T. A., Harms, P. D., Steel, P., & Credé, M. (2016). An assessment of the magnitude of effect sizes evidence from 30 years of meta-analysis in management. Journal of Leadership & Organizational Studies, 23(1), 66-81.
Hemphill, J. F. (2003). Interpreting the magnitudes of correlation coefficients. American Psychologist, 58, 78-80.
Richard, F. D., Bond Jr, C. F., & Stokes-Zoota, J. J. (2003). One Hundred Years of Social Psychology Quantitatively Described. Review of General Psychology, 7(4), 331-363
There are lots of criticisms of these estimates, but they are not a bad starting point for planning purposes. If you plug those numbers into a power calculator, you find that you need about 200 subjects to have 80% power for an average simple main effect (e.g., d = .4). If you want to be safe and either have higher power (e.g., 90%) or plan for a smaller effect size (e.g., d of .3), you’ll need more like 250 to 350 participants. This is pretty close to the sample size when effect sizes get “stable”.
Schoenbrodt & Perugini, 2013; http://www.nicebread.de/at-what-sample-size-do-correlations-stabilize/
However, for other types of analyses, like interaction effects, some smart people have estimated that you’ll need more than twice as many participants—in the range of 500. For example, Uri Simonsohn has shown that if you want to demonstrate that a manipulation can make a previously demonstrated effect go away, you need twice as many participants as you would need to demonstrate the original main effect (http://datacolada.org/17).
Whatever you do, be cautious about these numbers. Your job is to think about these issues not to use rules of thumb blindly. For example, the folks who study genetic effects found out that the effect sizes for single nucleotide polymorphisms were so tiny that they needed hundreds of thousands of people to have enough power to reliably detect their effects. On the flip side, when your effects are big, you don’t need many people. We know that the Stroop effect is both reliable and huge. You only need a handful of people to figure out whether the Stroop main effect will replicate. Your job is to use some estimated effect size to make an informed decision about what your sample size should be. It is not hard to do and there are no good excuses to avoid it.
Here some additional links and tables that you can use to estimate the sample size you will need to reach in order to achieve 80 or 90% power once you’ve got an estimate of your effect size:
For correlations:
https://power.phs.wakehealth.edu/index.cfm?calc=cor
For mean differences:
https://power.phs.wakehealth.edu/index.cfm?calc=tsm
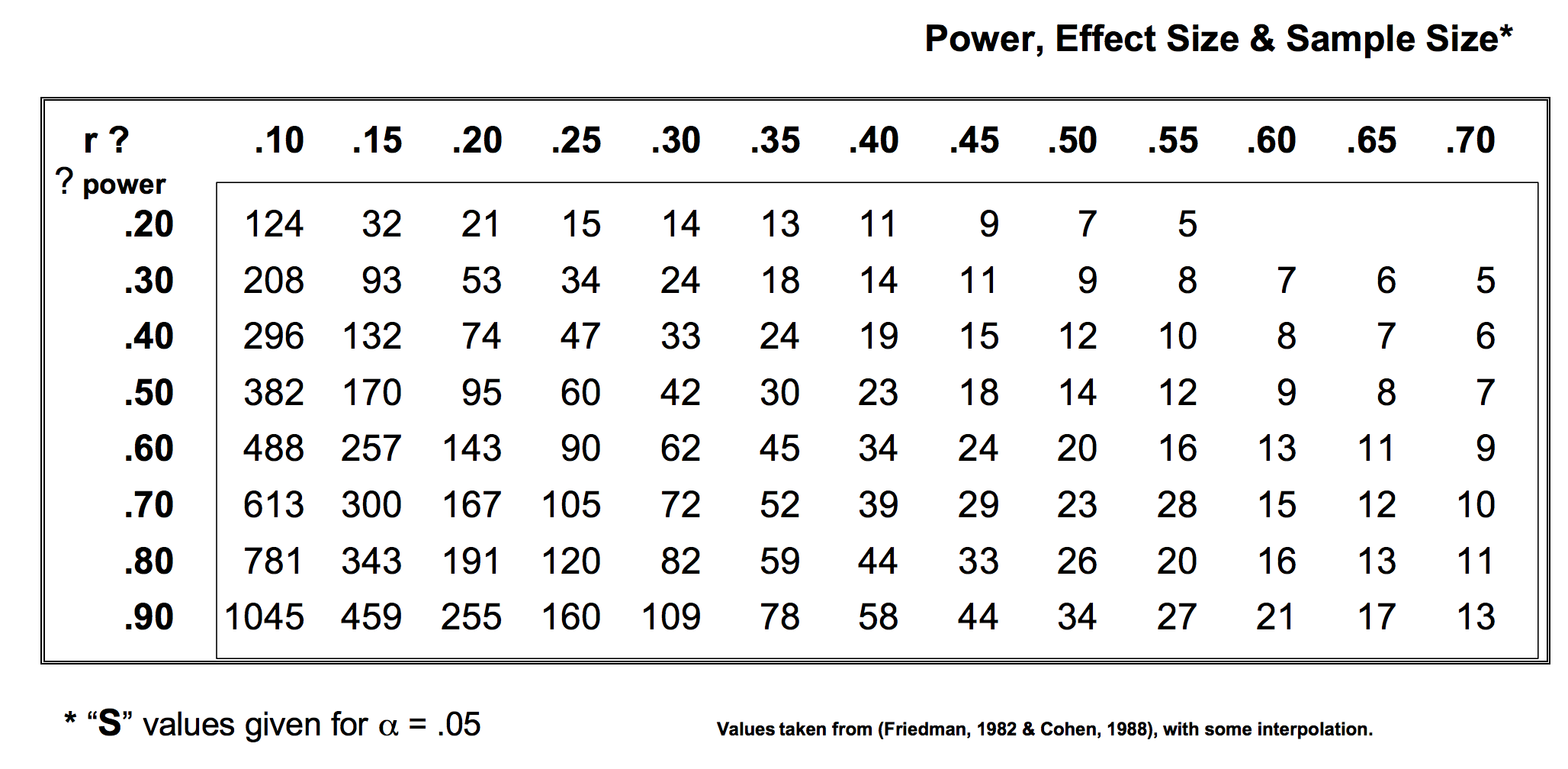
Here’s are two quick and easy tables showing the relation between power and effect size for reference:


Budlie Bond: My office-mate Chip Harkel says that there is a new rule of thumb that you should simply get 50 people per cell in an experiment. Is that a sensible strategy to use when I don’t know what the effect size might be?
Prof. Belfry-Roaster: The 50 person per cell is better than our previous rules of thumb (e.g., 15 to 20 people per cell), but, with a bit more thought, you can calibrate your sample size better. If you have reasons to think the effect size might be large (like the Stroop Effect), you will waste a lot of resources if you collect 50 cases per cell. Conversely, if you are interested in testing a typical interaction effect, your power is going to be too low using this rule of thumb.
Budlie Bond: Why is low power such a bad thing?
Prof. Belfry-Roaster: You can think about the answer several ways. Here’s a concrete and personal way to think about it. Let’s say that you are ready to propose your dissertation. You’ve come up with a great idea and we meet to plan out how you are going to test it. Instead of running any subjects I tell you there’s no need. I’m simply going to flip a coin to determine your results. Heads your findings are statistically significant; tails insignificant. Would you agree to that plan? If you find that to be an objectionable plan, then you shouldn’t care for the way we typically design our research because the average power is close to 50% (a coin flip). That’s what you do every time you run a low powered study—you flip a coin. I’d rather that you have a good chance of rejecting the null if it is false then to be subject to the whims of random noise. That’s what having a high powered study can do for you.
At a broader level low power is a problem because the findings from low powered studies are too noisy to rely on. Low powered studies are uninformative. They are also quite possibly the largest reason behind the replication crisis. A lot of people point to p-hacking and fraud as the culprits behind our current crisis, but a much simpler explanation of the problems is that the original studies were so small that they were not capable of revealing anything reliable. Sampling variance is a cruel master. Because of sampling variance, effects in small studies bounce around a lot. If we continue to publish low powered studies, we are contributing to the myth that underpowered studies are capable of producing robust knowledge. They are not.
Here are some additional readings that should help to understand how power is related to increasing the informational value of your research:
Lakens, D., & Evers, E. R. K. (2014). Sailing from the seas of chaos into the corridor of stability: Practical recommendations to increase the informational value of studies. Perspectives on Psychological Science, 9(3), 278–292. http://doi.org/10.1177/1745691614528520
Maxwell, S. E., Kelley, K., & Rausch, J. R. (2008). Sample size planning for statistical power and accuracy in parameter estimation. Annual Review of Psychology, 59(1), 537–563. http://doi.org/10.1146/annurev.psych.59.103006.093735
Budlie Bond: Is low power a good reason to dismiss a study after the fact?
Prof. Belfry-Roaster. Many people assume that statistical power is not necessary “after the fact.” That is, once we’ve done a study and found a significant result, it would appear that the study must have been capable of detecting said effect. This is based on a misunderstanding of p-values and significance tests (see Fraley & Marks, 2007 for a review).
Fraley, R. C., & Marks, M. J. (2007). The null hypothesis significance testing debate and its implications for personality research. Handbook of research methods in personality psychology, 149-169.
What many researchers fail to appreciate is that a literature based on underpowered studies is more likely to be full of false positives than a literature that is based on highly powered studies. This sometimes seems counterintuitive to researchers, but it boils down to the fact that, when studies are underpowered, the relative ratio of true to false positives in the literature shifts (see Ioannidis 2008). The consequence is that a literature based on underpowered studies is quite capable of containing an overwhelming number of false positives—much more than the nominal 5% that we’ve been conditioned to expect. If you want to maximize the number of true positives in the literature relative to false leads, you would be wise to not allow underpowered studies into the literature.
Ioannidis JPA (2008) Why most discovered true associations are inflated. Epidemiology, 19, 640-648.
In fact, I’d go one step further and say that low power is an excellent reason for why a study should be desk rejected by an editor. An editor has many jobs, but one of those is to elevate or maintain the quality of the work that the journal publishes. Given how poorly our research is holding up, you really need a good excuse to publish underpowered research because doing so will detract from the reputation of the journal in our evolving climate. For example, if you are studying a rare group or your resources are limited you may have some justification for using low power designs. But if that is the case, you need to be careful about using inferential statistics. The study may have to justified as being descriptive or suggestive, at best. On the other hand, if you are a researcher at a major university with loads of resources like grant monies, a big subject pool, and an army of undergraduate RAs, there is little or no justification for producing low-powered research. Low power studies simply increase the noise in the system making it harder and harder to figure out whether an effect exists or not and whether a theory has any merit. Given how many effects are failing to replicate, we have to start taking power seriously unless we want to see our entire field go down in replicatory flames.
Another reason to be skeptical of low powered studies is that, if researchers are using significance testing as a way of screening the veracity of their results, they can only detect medium to large effects. Given the fact that on average most of our effects are small, using low powered research makes you a victim of the “streetlight effect”—you know, where the drunk person only looks for their keys under the streetlight because that is the only place they can see? That is not an ideal way of doing science.
Budlie Bond: Ok, I can see some of your points. And, thanks to some of those online power calculators, I can see how I can plan my studies to ensure a high degree of power. But how do power calculations work in more complex designs, like those that use structural equation modeling or multi-level models?
Prof. Belfry-Roaster. There is less consensus on how to think about power in these situations. But it is still possible to make educated decisions, even without technical expertise. For example, even in a design that involves both repeated measures and between-person factors, the between-persons effects still involve comparisons across people and should be powered accordingly. And in SEM applications, if the pairwise covariances are not estimated with precision, there are lots of ways for those errors to propagate and create estimation problems for the model.
Thankfully, there are some very smart people out there and they have done their best to provide some benchmarks and power calculation programs for more complex designs. You can find some of them here.
Faul, F., Erdfelder, E., Lang, A. G., & Buchner, A. (2007). G* Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior research methods, 39(2), 175-191.
Lakens, D. (2013). Calculating and reporting effect sizes to facilitate cumulative science: a practical primer for t-tests and ANOVAs. Frontiers in psychology, 4, 863.
MacCallum, R. C., Browne, M. W., & Sugawara, H. M. (1996). Power analysis and determination of sample size for covariance structure modeling. Psychological methods, 1(2), 130-149.
Mathieu, J. E., Aguinis, H., Culpepper, S. A., & Chen, G. (2012). Understanding and estimating the power to detect cross-level interaction effects in multilevel modeling. Journal of Applied Psychology, 97(5), 951-966.
Muthén, B. O., & Curran, P. J. (1997). General longitudinal modeling of individual differences in experimental designs: A latent variable framework for analysis and power estimation. Psychological methods, 2(4), 371-402.
Budlie Bond: I wasn’t sure how to think about power when I conducted my first study. But, in looking back at my data, I see that, given the sample size I used, my power to detect the effect size I found (d = .50) was over 90%. Does that mean my study was highly powered?
Prof. Belfry-Roaster: When power is computed based on the effect size observed, the calculation is sometimes referred to as post hoc power or observed power. Although there can be value in computing post hoc power, it is not a good way to estimate the power of your design for a number of reasons. We have touched on some of those already. For example, if the design is based on a small sample, only large effects (true large effects and overestimates of smaller or null effects) will cross the p < .05 barrier. As a result, the effects you see will tend to be larger than the population effects of interest, leading to inflated power estimates.
More importantly, however, power is a design issue, not a data-analytic issue. Ideally, you want to design your studies to be capable of detecting the effects that matter for the theory of interest. Thus, when designing a study, you should always ask “How many subjects do I need to have 80% power to detect an effect if the population effect size is X or higher,” where X is the minimum effect size of interest. This value is likely to vary from one investigator to another, but given that small effects matter for most directional theories, it is prudent to set this value fairly low.
You can also ask about the power of the design in a post hoc way, but it is best to ask not what the power was to detect the effect that was observed, but to ask what the power was to detect effects of various sizes. For example, if you conducted a two-condition study with 50 people per cell, you had 17% power to detect a d of .20, 51% to detect a d of .40, and 98% to detect a d of .80. In short, you can evaluate the power of a study to detect population effects of various sizes after the fact. But you don’t want to compute post hoc power by asking what the power of the design was for detecting the effect observed. For more about these issues, please see Daniel Lakens great blog post on post-hoc power: http://daniellakens.blogspot.com/2014/12/observed-power-and-what-to-do-if-your.html
Budlie Bond: Thanks for all of the background on power. I got in a heated discussion with Chip again and he said a few things that made me think you are emphasizing power too much. First he said that effect sizes are for applied researchers and that his work is theoretical. The observed effect sizes are not important because they depend on a number of factors that can vary from one context to the next (e.g., the strength of the manipulation, the specific DV measured). Are effect sizes and power less useful in basic research than they are in applied research?
Prof. Belfry-Roaster: With the exception of qualitative research, all studies have effect sizes, even if they are based on contrived or artificial conditions (think of Harlow’s wire monkeys, for example). If researchers want a strong test of their theory in highly controlled laboratory settings, they gain enormously by considering power and thus effect sizes. They need that information to design the study to test their idea well.
Moreover, if other people want to replicate your technique or build on your design, then it is really helpful if they know the effect size that you found so they can plan accordingly.
In short, even if the effect size doesn’t naturally translate into something of real world significance given the nature of the experimental or lab task, there is an effect size associated with the task. Knowing it is important not only for properly testing the theory and seeing what kinds of factors can modulate the effect, but for helping others plan their research accordingly. You are not only designing better research by using effect sizes, you are helping other researchers too.
Another reason to always estimate your effect sizes is that they are a great reality check on the likelihood and believability of your results. For example, when we do individual difference research, we start thinking that we are probably measuring the same thing when the correlation between our independent and dependent variable gets north of .50. Well, a correlation of .5 is like a d-score of .8. So, if you are getting effect sizes above .5 or above a d of .8 your findings warrant a few skeptical questions. First, you should ask whether you measured the same thing twice. In an experiment d’s around 1 should really be the exclusive domain of manipulation checks, not an outcome of some subtle manipulation. Second, you have to ask yourself how you are the special one who found the “low hanging fruit” that is implicit in a huge effect size. We’ve been at the study of psychology for many decades. How is it that you are the genius who finally hit on a relationship that is so large that it should visible to the naked eye (Jacob Cohen’s description of a medium effect size) and all of the other psychologists missed it? Maybe you are that observant, but it is a good question to ask yourself nonetheless.
And this circles back to our discussion of low power. Small N studies only have enough power to detect medium to large effect sizes with any reliability. If you insist on running small N studies and ignore your effect sizes, you are more likely to produce inaccurate results simply because you can’t detect anything but large effects, which we know are rare. If you then report those exaggerated effect sizes, other people who attempt to build on your research will plan their designs around an effect that is too large. This will lead them to underpower their studies and fail to replicate your results. The underpowered study thus sets in motion a series of unfortunate events that lead to confusion and despair rather than progress.
Choosing to ignore your effect sizes in the context of running small N studies is like sticking your head in the sand. Don’t do it.
Budlie Bond: Chip’s advisor also says we should not be so concerned with Type 1 errors. What do you think?
Prof. Belfry-Roaster: To state out loud that you are not worried about Type 1 errors at this point in time is inconceivable. Our studies are going down in flames one-by-one. The primary reason for that is because we didn’t design the original studies well—typically they were underpowered and never directly replicated. If we continue to turn a blind eye to powering our research well, we are committing to a future where our research will repeatedly not replicate. Personally, I don’t want you to experience that fate.
Budlie Bond: Chip also said that some people argue against using large samples because doing so is cheating. You are more likely to get a statistically significant finding that is really tiny. By only running small studies they say they protect themselves from promoting tiny effects.
Prof. Belfry-Roaster: While it is true that small studies can’t detect small effects, the logic of this argument does not add up. The only way this argument would hold is if you didn’t identify the effect size in your study, which, unfortunately, used to be quite common. Researchers used to and still do obsess over p-values. In a world where you only use p-values to decide whether a theory or hypothesis is true, it is the case that large samples will allow you to claim that an effect holds when it is actually quite small. On the other hand, if you estimate your effect sizes in all of your studies then there is nothing deceptive about using a large sample. Once you identify an effect as small, then other researchers can decide for themselves whether they think it warrants investment. Moreover, the size of the sample is independent of the effect size (or should be). You can find a big effect size with a big sample too.
Ultimately, the benefits of a larger sample outweigh the costs of a small sample. You gain less sampling variance and a more stable estimate of the effect size. In turn, the test of your idea should hold up better in future research than the results from a small N study. That’s nothing to sneeze at.
You can also see how this attitude toward power and effect sizes creates a vicious cycle. If you use small N studies evaluated solely by p-values rather than power and effect sizes, you are destined to lead a chaotic research existence where findings come and go, seemingly nonsensically. If you then argue that 1) all theories are not true under certain conditions, or that 2) the manipulation is delicate, or 3) that there are loads of hidden moderators, you can quickly get into a situation where your claims cannot be refuted. Using high powered studies with effect size estimates can keep you a little more honest about the viability of your ideas.
Budlie Bond: Chip’s advisor says all of this obsession with power is hindering our ability to be creative. What do you think?
Prof. Belfry-Roaster: Personally, I believe the only thing standing between you and a creative idea is gray matter and some training. How you go about testing that idea is not a hindrance to coming up with the idea in the first place. At the moment we don’t suffer from a deficit of creativity. Rather we have an excess of creativity combined with the deafening roar of noise pollution. The problem with low powered studies is they simply add to the noise. But how valuable are creative ideas in science if they are not true?
Many researchers believe that the best way to test creative ideas is to do so quickly with few people. Actually, it is the opposite. If you really want to know whether your new, creative idea is a good one, you want to overpower your study. One reason is that low power leads to Type II errors—not detecting an effect when the null is false. That’s a tragedy. And, it is an easy tragedy to avoid—just power your study adequately.
Creative ideas are a dime a dozen. But creative ideas based on robust statistical evidence are rare indeed. Be creative, but be powerfully creative.
Budlie Bond: Some of the other grad students were saying that the sample sizes you are proposing are crazy large. They don’t want to run studies that large because they won’t be able to keep up with grad students who can crank out a bunch of small studies and publish at a faster rate.
Prof. Belfry-Roaster: I’m sympathetic to this problem as it does seem to indicate that research done well will inevitably take more time, but I think that might be misleading. If your fellow students are running low powered studies, they are likely finding mixed results, which given our publication norms won’t get a positive reception. Therefore, to get a set of studies all with p-values below .05 they will probably end up running multiple small studies. In the end, they will probably test as many subjects as you’ll test in your one study. The kicker is that their work will also be less likely to hold up because it is probably riddled with Type 1 errors.
Will Gervais has conducted some interesting simulations comparing research strategies that focus on slower, but more powerful studies against those that focus on faster, less powerful samples. His analysis suggests that you’re not necessarily better off doing a few quick and under-powered studies. His post is worth a read.
http://willgervais.com/blog/2016/2/10/casting-a-wide-net
Budlie Bond: Chip says that your push for large sample sizes also discriminates against people who work at small colleges and universities because they don’t have access to the numbers of people you need to run adequately-powered research.
Prof. Belfry-Roaster: He’s right. Running high powered studies will require potentially painful changes to the way we conduct research. This, as you know, is one reason why we often offer up our lab to friends at small universities to help conduct their studies. But they also should not be too distraught. There are creative and innovative solutions to the necessity of running well-designed studies (e.g., high powered research). First, we can take inspiration from the GWAS researchers. When faced with the reality that they couldn’t go it alone, they combined efforts into a consortium in order to do their science properly. There is nothing stopping researchers at both smaller and larger colleges and universities from creating their own consortia. It might mean we have to change our culture of worshiping the “hero” researcher, but that’s okay. Two or more heads is always better than one (at least according to most groups research. I wonder how reliable that work is…?). Second, we are on the verge of technological advances that can make access to large numbers of people much easier—MtTurk being just one example. Third, some of our societies, like SPSP and APS and APA are rich. Well, rich enough to consider doing something creative with their money. They could, if they had the will and the leadership, start thinking about doing proactive things like creating subject pool panels that we can all access and run our studies on and thus conduct better powered research.
Basically Bud, we are at a critical juncture. We can continue doing things the old way which means we will continue to produce noisy, unreplicable research, or we can change for the better. The simplest and most productive thing we can do so is to increase the power of our research. In most cases, this can be achieved simply by increasing the average sample size of our studies. That’s why we obsess about the power of the research we read and evaluate. Any other questions?